推荐feed特征储存以及计算方式概要
特征存储
特征主要分为两个部分:视频特征,用户特征。特征存储同时分为离线和实时两个部分。离线部分主要交给hadoop,实时主要为业务和redis进行计算。
离线特征数据
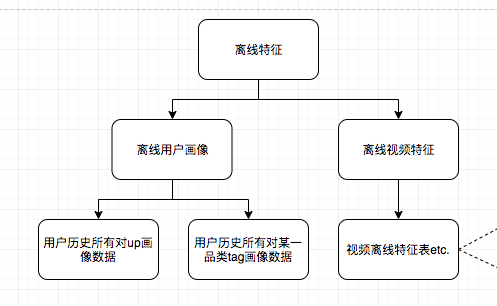
用户离线数据
用户离线数据主要分为两块(后新增cluster聚类品类,与品类tag类似):
- 用户历史上对up的画像数据
- 用户历史上对品类tag的画像数据
需要记录用户历史上对该up或者对该品类tag的画像数据,可以在计算的时候带上上一次的数据,SQL上表现为此次计算结果union all上一次结果,并在外层进行sum合并。
目前线上对up或者对tag都由两张表构成。
idm表作为中间表记录用户对up/tag的所有行为数据,其中一行为一个用户对某一个up/tag的数据;adm表作为计算结果表记录,其中一行为一个用户对其所有发生过操作行为的up/tag的数据。feature服务直接获取这张hive表原始数据进行解析,后存储feature离线特征库redis。
视频离线数据
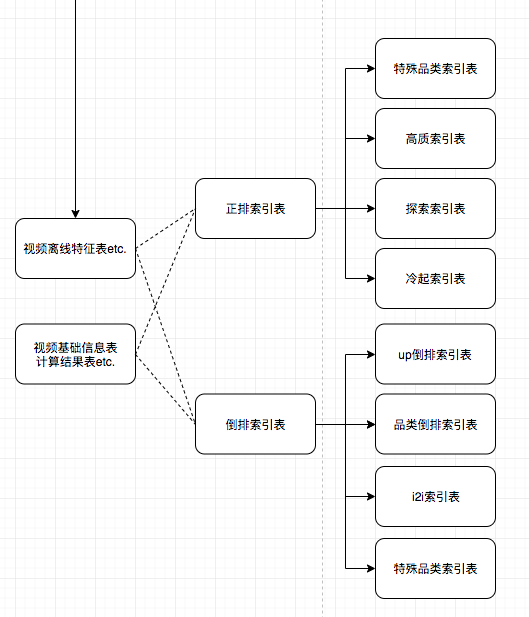
其中视频特征表由多张上游表汇集而成,其中包括:视频基础信息表,视频下发记录表,视频点击记录表,视频播放完成率表,视频互动数据表,视频推荐分表。这些表又各自依赖多张数据表。
根据地视频的离线特征,依次得出所需的正排索引表,倒排索引表,这个过程可能还需要用到类似于视频信息表,计算结果表等。比如像i2i索引表,i2i是通过离线算法库的方法计算得出,其join特征表,补完特征。
实时特征数据
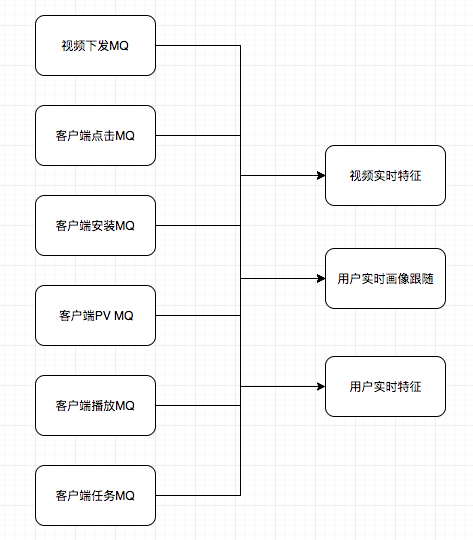
实时特征表主要由MQ获取消息数据,并计算存入实时特征库。当feature服务提供对外结果时,再将数据从实时特征库获取返回给调用方。
1. 视频实时特征
视频实时特征主要为视频的展现数、点击数、两者计算得出的实时CTR,以及 根据视频的实时互动率计算得出的实时互动分。另外还有该视频的最后一次下发时间,最后一次被点击视频,视频实时播放完成率,视频次播率等。
视频实时ctr的方式:
实时CTR表征的是视频近期得实时点击率,为了得到『近期』与『实时』就需要一个时间范围以及展现阈值,当展现值过少,往前追展现值,并限定最少和最多时间范围。
这里使用的是滑动时间窗口当计算方式。当视频的展现数不满足200时,往前最时间窗口,最大追溯7天,当视频3天内展现数满足200时,即取3天的时间窗口。并获得此时间窗口来获取点击数。
这里将数据存储在redis zset结构中。
以vid为key,score为点击数,value为行为类型+时间段时间戳,这样就将一段时间内的行为聚合。(目前是使用这样的方式可以计算CTR,并且计算互动分的)
实际计算CTR另一种方式,大同小异,也是使用追溯时间窗口方式。具体方式为:并非使用zset结构,而是将不同时间段的key作为redis一个单独的key-value键值对,然后mget获取值。由于时间关系没有讲后一种改为前一种。(虽然数据已经run起来了,改动不大
2. 用户实时画像&用户画像分数计算
engine请求feature的返回结果用以召回用户画像索引。
feature存储离线和实时两部分用户画像,并且两者都是按照用户对up或者品类tag的ctr得出分数的。只是计算方法稍有不同。
实时分数计算公式
- 若 sessionClickNum 大于 avgClickNum ,当前session中的对up/tag的点击次数大于平均up/tag的点击次数:
- 若小于
离线分数计算公式
- 若 sessionClickNum 大于 avgClickNum ,当前session中的对up/tag的点击次数大于平均up/tag的点击次数:
- 若小于
其中timeless为历史画像分数随时间衰减算法得出因子。
参考: 牛顿冷却定律-阮一峰的网络日志
代码表现为:
private double getCurrentTimeScore(Long eventTime) {
double cofficient = 0;
Long defaultExceptionEventTime = 0L;
if (defaultExceptionEventTime.equals(eventTime)) {
cofficient = Math.pow(Math.E,
COOLING_COEFFICIENT * (double) (24 * 60));
} else {
cofficient = Math.pow(Math.E, COOLING_COEFFICIENT
* (double) ((System.currentTimeMillis() - eventTime)
/ 1000 / 60));
}
return cofficient;
}