推荐引擎和广告检索引擎的异同
1. 背景
之前做海外短视频的推荐引擎,后面转做竞价广告的检索引擎(再后面转做品牌广告),所以一直想写下这两者:推进引擎/竞价广告检索引擎的异同。
2. 流程概览
2.1 推荐场景流程概览:
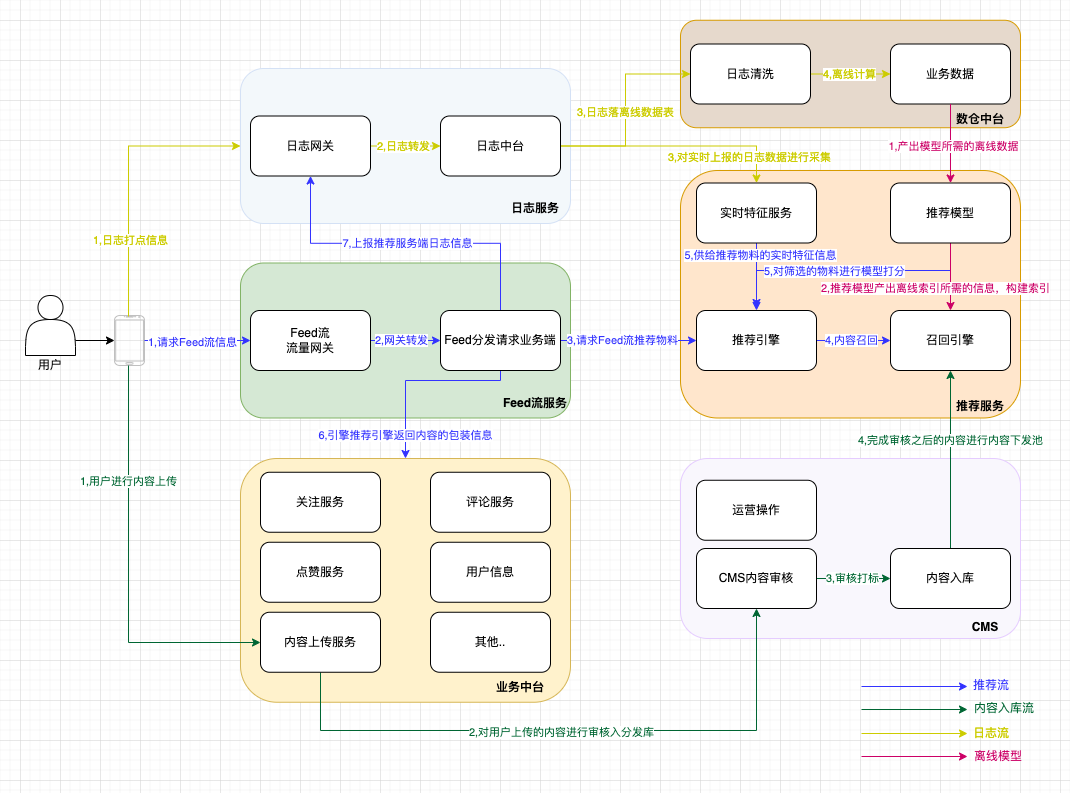
2.2 广告场景流程概览

3. 物料/来源/入实时流
当时从推荐团队到广告团队的一个原因,就是两者业务逻辑是相似。
都是将物料从召回、过滤、打分、排序、选择(渲染),这样的流程下发到下游,下游再进行曝光、点击、转化等回流数据到后端。
3.1 物料量级
从物料量上来讲,我经历的两个团队的物料量是不在一个量级的,推荐的物料量要远远大于广告创意。视频的物料池包括UGC,PGC视频等应该有几十亿之多。广告的物料库不到千万级,如果是某一个时刻能够进行投放的物料,大概只有数万量级。
当然不同的广告团队,业务场景会有很大的不同,不过这相对符合直观的认知,一个平台的内容应该远远高于在这个平台进行投放的广告的。
3.2 物料来源
从物料的来源的说,推荐的内容来自于用户上传、达人(签约用户)生产,或者从爬虫得到的网络资源。内容质量参差不齐,而且五花八门,所以会经过机神、多层人工审核、复审、打标等等流程。
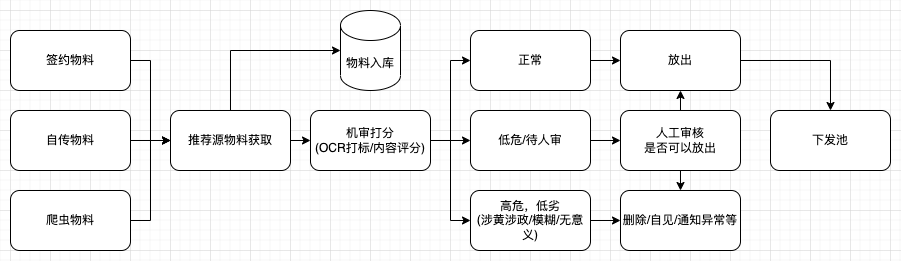
但是广告创意就会对内容的把控明确得多,广告主上传的创意绝大部分是符合进行投放广告位的要求的,比如图片/视频的宽高/码率等,如果出现了这样的情况,基本在广告创意阶段就会在创建阶段就会拦截,返回给客户不合规的具体情况;以及广告内容也是基本满足要求(很少出现涉黄涉政等不合规的情况),同时在进行投放的时候,客户也能够主动选择定向、行业等信息,一定程度来补充物料信息,在通过人工审核等基本就能够投放要求。
3.3 物料下发
3.3.1 推荐场景
推荐的物料来源从五花八门,所以会经过层层审核。因为推荐场景更多的是关注的物料本身,而且物料的分发和广告场景有很大的不同,接近于高分者得(当然也会有用户兴趣ee等场景,所以会让低分物料下发)。
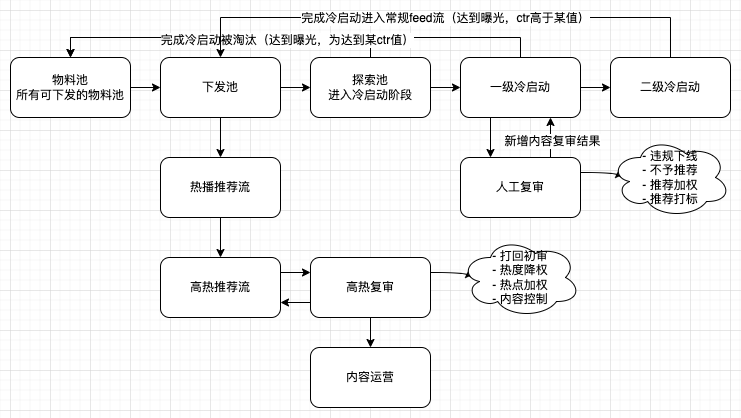
物料入库随即就会进行审核打标,使物料获得基本信息;然后进行物料的探索,一般来说会进行多轮的探索(但是在某些不太精细的场景也只有一轮)。
如果给足了一定的探索机会(一般来说是曝光额度),物料没有达到预期的指标,如ctr,cvr等等,物料就会进入物料库,再下一轮索引构建的时候通过其他方式才有可能下发;而达到预期指标的物料,会进入推荐的常规池或者热播池,属于是相对精品的内容,可以分发到用户侧,提升用户的指标vv,ts等。另外提一下,探索视频往往是降指标的,所以一般也不会给新用户或者易流失用户下发探索视频。
其实热播视频,也会经历几个热播池,最后来到高热池。此时往往会进入到运营干预阶段,给物料降权,加权,或者进行内容运营(热搜,话题,造势)等等,将运营获取得到的信息再进入feed流分发,同时内容运营也会在其他的流量入口分发流量。
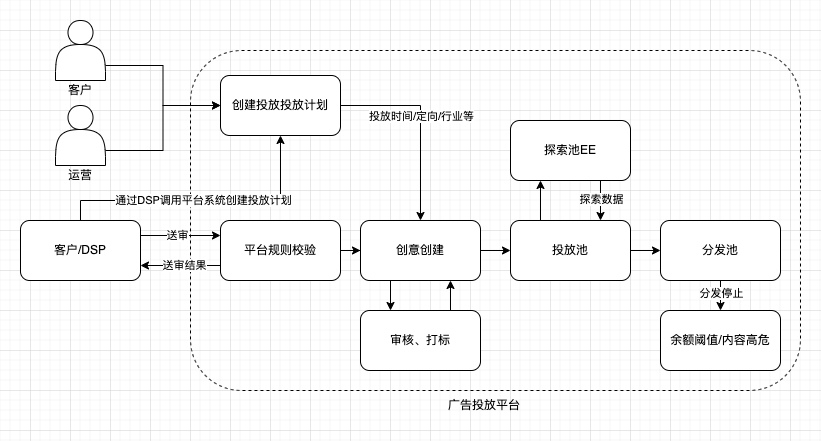
3.3.2 广告场景
对于广告场景来说,一般不会经过那么多轮的审核。在广告创意完成内容审核之后,就会进入创意的下发池。
广告相对推进,它更关注的是广告主的利益,所以首先就会满足一些订单合同上约定的内容,比如创意投放的时间/地域/特殊定向等,其次在完成了EE之后(积累一定的创意信息,便于模型计算),创意的模型质量打分(如ctr)不是很高,在某些情况也会进行投放,尽管这样会伤害到用户体验。
最明显的就是品牌广告中PDB类型的订单,不过在竞价广告中也会存在这样的情况,由于最后的竞价bid有广告出价这个因子,所以对于出价高的创意,自然最后得分就可能更高,就更可能投放。
然后,是创意的分发会进行费用的扣减,所以当费用撞线的时候,也就会停止创意的分发。即使创意热度再高,质量再好,也不会再进行分发。
另外,在大部分情况广告主希望的是创意进行平滑的投放,不是在某一个很短的时间就把预算花完,所以会有很多对创意维度的频控策略。推荐则是某一个内容爆火之后就会迅速蹿升,甚至后面会有运营在造势。

4. 实时流程
对于实时流程,推荐流程和广告流程的目的是一致的,都是从库中获取物料,然后分发出去。但因为推荐和广告各自服务的目的是不一样的,所以物料在系统中扭转的模块会不一致。比如推荐系统会对不足的视频补齐,会添加多样化的逻辑;广告系统会余额判断,预算平滑等等。
4.1 广告场景
我所在的支付宝广告团队,由于其集成了很多支付宝平台能力,所以例如像abTest,日志采集(由SLS实现)等功能就交由平台实现。
广告检索引擎是从物料库中获取广告数据,然后得到系统分发的物料,所以检索引擎是充当的一个dsp,负责提供创建。在AdExchange接收到媒体端的请求后,向dsp发起请求,此时dsp获取得到相关的请求数据,然后进行判断/abtest打标,然后按照各个模块一次处理。流程图如下:
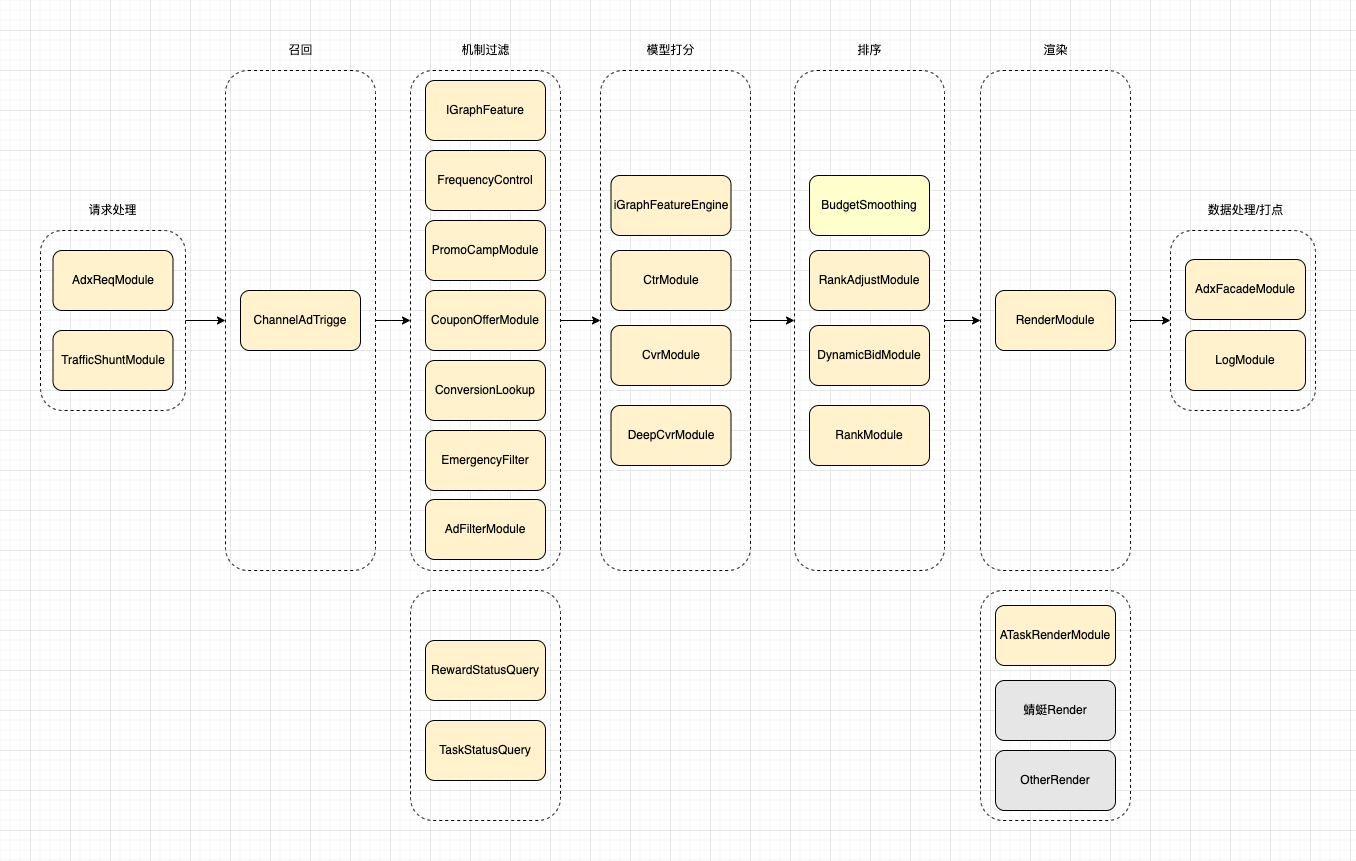
4.1.1 请求处理
检索引擎在获取到adx请求之后,先对请求进行拆解,并且其中的当前所需的必要信息,比如userId,以及请求的是哪个场景等等。然后才能进行adTest打标,以及确定应该召回哪个部分的广告?例如端内某个场景的广告,还是端外的广告。
4.1.2 召回
得到需要召回的广告所在的场景之后,就可以请求召回引擎,根据对应的定向,过滤条件等获取当前正在投放的广告。当一个广告暂停投放之后,会在更新db的时候发出event,来告知召回引擎下线该广告,这个时候会有一定的延时(但几乎可以忽略),所以在检索引擎中还会根据广告的信息和状态进行过滤。
这里的召回引擎,由阿里的内部平台Ha3和千鲟提供,Ha3负责的是进行广告的定向和过滤条件的匹配,充当召回引擎;千鲟提供了平台功能,提供增加和删除Ha3索引和字段,定期全量和增加导入Ha3数据的能力。
在召回广告的时候,往往会提供了一个截断值x,获取前x的广告,避免增大系统压力,同时也能降低处理时间。
4.1.3 机制过滤
获取广告之后,为了去除不需要的广告,以及降低排序的长度,减少模型压力,会进行过滤。过滤的方式和手段很多,而且不同的平台有不同的过滤机制,这里就不一一介绍,仅提及其中较为重要的部分。
-
频次过滤:某个用户对某个广告或者某类广告会有一定的展示阈值,当高于这个阈值时需要去除这个广告。
-
紧急过滤:某些广告由于合规的要求,或者某些特殊情况,需要紧急下线的时候,会在这里杯过滤掉。
-
活动内容过滤:支付宝的某些广告常常会带有优惠券或者其他活动信息,这些活动信息在营销平台下线之后,可能不会及时同步到广告上,所以引擎需要在过程中请求营销获取平台获取是否还在活动中或是否还有优惠券等信息,然后判断是否过滤。
这里提一下支付宝广告引擎中所做的过滤的方法:从召回引擎获取的广告是一个列表,过滤之后需要记录哪些广告是不可再用的,以及对应的被过滤的原因。比如广告id对应的值,一个Byte,一个大B是4个bit,将其中一位置成1,则表示其被这一位的原因给过滤了。如果任何一位都不为1,说明这个广告是没有被过滤的,是可用的。
4.1.4 模型打分
过滤完成之后,获取到可用的广告列表。此时通过用户id和广告id进行某些特征的获取,然后交由模型打分,包括ctr模型,cvr模型等。打分完成,获取得到对应每个广告的ctr和cvr信息。
4.1.5 排序
排序的依据的score分数,在广告引擎中,这个分数是eCPM,千次曝光的消耗。我们模型打分完成之后,可以根据对应的后验ctr,cvr,以及广告主的出价bid值,算出eCPM值,然后进行排序。在排序完成之后,还需要记录此次广告胜出时候的出价,一般情况在广告引擎中是使用的二价的值,也就是top1的到的广告的出价不会使用,而是使用排序第二的广告的广告主的出价。
使用二价计费的主要目的是为了维持整个广告引擎的收入和系统稳定,如果是一价计费,可能导致系统的收入有时会变得特别高,在广告主投广告的意愿低峰,收入会变得特别低。同时也让广告主更容易猜到平台的最低价在哪儿。
4.1.6 渲染
这一部分是我之前在做推荐系统时所没有的。支付宝的广告场景特别多,在同一个广告位也可以展示不同的广告形态,获取到广告之后,还可以交由模型,告诉系统这个广告应该选择哪个广告模版以达到最佳的展示效果。
根据广告模版,渲染广告结果,得到将返回给AdExchange的广告内容。
4.1.7 数据处理
在返回Adx之前,还需要记录当次请求,得出的广告是哪一个,在这次请求中哪些广告被过滤了,以及过滤原因是什么等等。记录下这些信息到日志中,会通过SLS发送给数据平台,然后在处理,统计或者进行问题排查。
在广告引擎的问题排查过程中,经常遇到的也即是,xx广告为什么没有出,xx广告为什么没有消耗或者消耗比较慢?等等。这些问题往往能在日志中找到相关信息。
4.2 推荐场景
在上面也有提到,推荐场景的物料和广告不是在一个数量级的,并且因为所服务的业务逻辑也不相同,所以在流程上会体现一些不同。推荐的流程图如下:
4.2.1 请求处理
推荐场景的上游是Feed流业务层,它来包装推荐的返回数据和广告数据以及一些活动数据等。推荐引擎收到它的请求之后,会首先进行请求处理,拆解出请求中的重要信息,比如设备id,用户id等等,以此来进行用户特征的请求(比如当前用户是否为新用户,当前用户最近的观看视频列表,喜欢的视频类型等等),以及对请求进行abTest的打标,便于在接下来的流程中进行ab实验。
4.2.2 召回
不同的用户对应的召回策略是不相同的,如新用户,因为其对“不好”视频的容忍度是很低的,需要尽可能的推送高质视频给新用户。在新用户首刷视频中,可能包含人工筛选的视频,以达到视频尽可能高质的目的。
如对于老用户,则会召回高热视频,根据用户观看过/喜欢的视频的i2i分支得到的视频列表,根据用户喜欢的tag得到的视频列表等等,这部分是根据偏好得到的视频。还需要获取部分用户没有接触过的类型的视频,这是因为如果一直推送用户喜欢的类型视频,那么用户的兴趣就会不断缩窄,是不利于视频分发和用户的兴趣探索的。
另外对于老用户,还需要召回新上传的视频,让老用户给这些新视频反馈,以判断这些新视频的质量好坏。
4.2.3 过滤
类似于抖音,快手,某些视频只有给用户分发过了,就不会再分发给用户了。而这部分工作在召回阶段是无法完成的,所以会在召回完成之后,对获取得到的视频列表进行过滤。其中也就包含,对用户看过的视频列表进行过滤(用户看过的视频列表会保存在用户的特征列表中)。此外还有类似于对用户不喜欢的tag过滤,视频过长的过滤,视频状态已经被删除,被ban的过滤等等。
另外还有一些机制上的过滤,和广告引擎一样,不同的业务场景都有不同的机制。比如节日类的过滤,如当天是中秋节,那么相关的视频可能就会非常火爆,直到第二天,视频的火热程度可能都不会有太大的衰减,那么就需要进行这部分机制上的过滤,避免推送给用户过时的视频。
4.2.4 截断
这部分是为了降低系统的压力增设的,尽管过滤之后,会减少很多视频,但是由于召回的量级很大,此时可能仍然包含较多的视频。所以需要截断,获取按照离线分数的top x的视频。
4.2.5 特征合并
推荐系统的召回的物料是有内存索引提供的,所以如果我们将一些当次请求的数据赋值到召回的列表中,那么会污染到内存索引,并且也是线程不安全的。所以在截断之后,我们需要新创建一个视频列表,即从获取得到的视频列表拷贝一份。之后我们才能在视频列表中添加特征,分数等等。
4.2.6 排序
在这里,为了减轻模型的压力,在模型排序之前,会先用后验的ctr,cvr等数据进行排序,然后再进行截断取top n的视频。再交给模型排序。
这里的后验特征和分值,是由特征服务统计并计算的。当打点日志上报,向用户展示了一个视频或者用户观看了一个视频等等,特征服务会根据这样的消息,存储数据并计算对应的ctr,cvr等等。然后再推荐引擎需要的时候,提供api查询对应的视频的特征和分值。而不用推荐引擎拿到特征再计算。
后验特征排序截断完成之后,就交由模型进行排序,模型给出计算的Q值(通常为ctr),然后再返回给推荐引擎进行计算。根据模型得出的Q值和融合排序公式,得到视频列表的相对序。
4.2.7 选择
排序完成之后,结果往往是用户之前没有接触过的视频品类或者冷门视频,是不能排序到前面的,这个时候需要在机制上挑选部分这样的视频,让用户能够进行兴趣探索,以便之后接触更多的视频。比如一次推荐会分发10个视频,那么其3,5个视频位置可能就会让给这些兴趣探索的视频。
另外还有新视频也往往不如热门视频分数高,也需要在机制上给新视频一定的位置,让其能够分发。
4.2.8 填充打点
选择完成之后,得到一个可以分发的视频列表,此时还需要获取一些视频的包装信息,如:视频的封面图,视频地址,描述等等。并且还需要通过实时接口获取视频的状态,如果当前的视频是下架视频,这里还会进行一次过滤(虽然召回列表中视频会被更新,但是更新的频率很低,需要实时接口保证)。
经过前面的处理逻辑,可能原本召回的视频列表(有数万个视频),在选择之后,不足10个视频,那么就需要用缓存池中的视频对前面的流程中得到的视频列表进行填充。在推荐场景,与其推送一个用户不那么喜欢的视频,也好过什么都不给用户推送或者让用户只能看到一两个视频。
此时,获取得到的视频列表可以返回给上游了。但在返回之前还需要记录哪些视频被返回了,返回时候的视频的特征是怎样的,哪个用户请求了这个视频等信息。这些信息会以消息的形式发送给消息中心,然后将其数据落地,之后进行分析,数据统计,以及特征,模型计算等等。
5. 总结
推荐视频和广告创意从实时请求返回到上游,还有诸多不同,比如推荐可能对数据的采集更多样化,包括用户的展示,点击,点赞,dislike,对uploader的关注,点击进个人页,评论等等都会进行数据采集,以便获取用户的更详细兴趣。而广告场景,每一次展示都会计费,所以对数据的准确性就要求很高,其中还可能会包含第三方检测服务的打点上报等等。
由于之前负责过推荐引擎和广告引擎相关工作,所以在工作中会感觉到两者的一些相似和不同处,由此就想着记录一下。不过这里只介绍了物料入库和实时分发的部分逻辑。对于之后的包装,展示,以及数据计算/分析/统计等等就没有展开介绍了。