AI Explore - AI探索
Status AI状态
现在如果不是后端代码,我基本都是用AI(主要是Claude Code)来帮我完成了。
之前我还会去学习像是Swift开发APP的语法、异步逻辑、加载优先级等等,现在基本都交由AI来完成了。代码对于我来说完成是黑盒的状态,即不知道它怎么实现的、也不知道其中的数据结构是什么。
举例:
我在开发 NomoWallet (诺莫记账) 这款APP的时候,其中有一个界面是记账、然后添加分类。这个分类会在很多地方使用,比如设置中心中可以添加和删除分类;在总览目录中会展示分类;近期交易中也会展示分类。但是这个分类是如何和设置中的关联的、以及每一笔交易中添加的分类如何与记账页面中的分类关联的,我不太清楚。

如果是我来设计的话,分类需要有一个Entity ID,那么交易中添加的分类需要绑定这个ID,不论分类如何起名,ID一直跟随这个分类。这样相当于是把每一个icon设置成了Entity实体,按理来说也没有问题。但是比如用户导入的数据,如何给它分配ID呢?此时使用名字可能就方便很多。比如用户在以前的交易中设置的是“餐饮”这样的一个分类,那么在当前APP直接匹配餐饮就能显示了。再比如用户在设置页面中删除了某个分类,之后又想添加回来,但是记录又很多,总不能一条条的编辑,这个时候使用名字直接匹配添加回来的分类,又是能Work的。但是这些和ID都是脱钩的。
在实际实现上,AI的开发方式应该是没有设置ID的,使用的是名字匹配的方式,具体的一些匹配规则我也不是太清楚。但是就我设置的一些边界条件和亲自验证之后,都能满足我设定的需求,所以应该是没有问题的。但是这种黑盒总有种让人惴惴不安的感觉。
我想在一些生产环境,恐怕是不允许这种黑盒的出现吧。
Explore AI探索
AI对文本的处理很强,但是对于图像的理解很弱。我在想能否文本的方式来告诉AI图片内容,这样AI能够帮我去修改图片那种,做更强的定制化。
所以我写了 BlueStarPixel 蓝星像素 这款MacOS上的应用,它能够将图片转换成像素点,来呈现像素图。也能将视频抽帧来显示多个像素图。
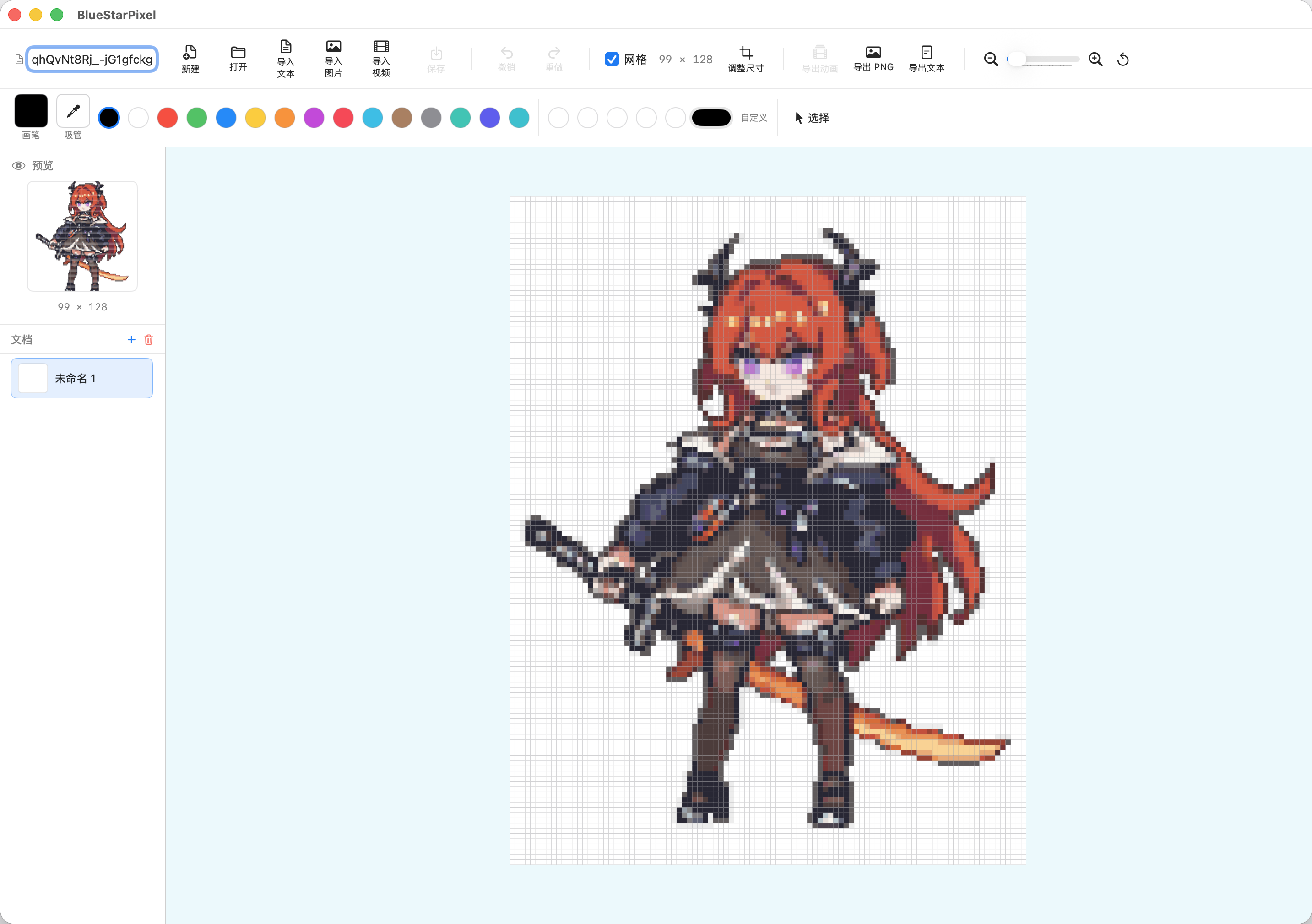
并且这个像素图是可以导出成文本的,文本的编码规则如下:
================================================================
BlueStarPixel ASCII Art Format Specification
================================================================
This file describes a pixel art image using plain text.
It consists of two required sections: 'palette' and 'grid'.
Lines starting with '#' or '//' are comments and can be ignored.
--- Palette Section ---
Starts with the keyword 'palette' on its own line.
Each following line defines one color mapping:
<char> <r> <g> <b> <a>
- <char>: a single character used to represent this color in the grid
- <r>, <g>, <b>, <a>: red/green/blue/alpha components in range 0.0 ~ 1.0
- The special character '.' represents fully transparent (clear) pixels
--- Grid Section ---
Starts with the keyword 'grid' on its own line.
Each following line represents one horizontal row of pixels.
Every character in a row maps to one pixel via the palette above.
The total number of rows equals the image height.
The number of characters per row equals the image width.
================================================================
比如一个小鸟站在树枝上的像素图如下:
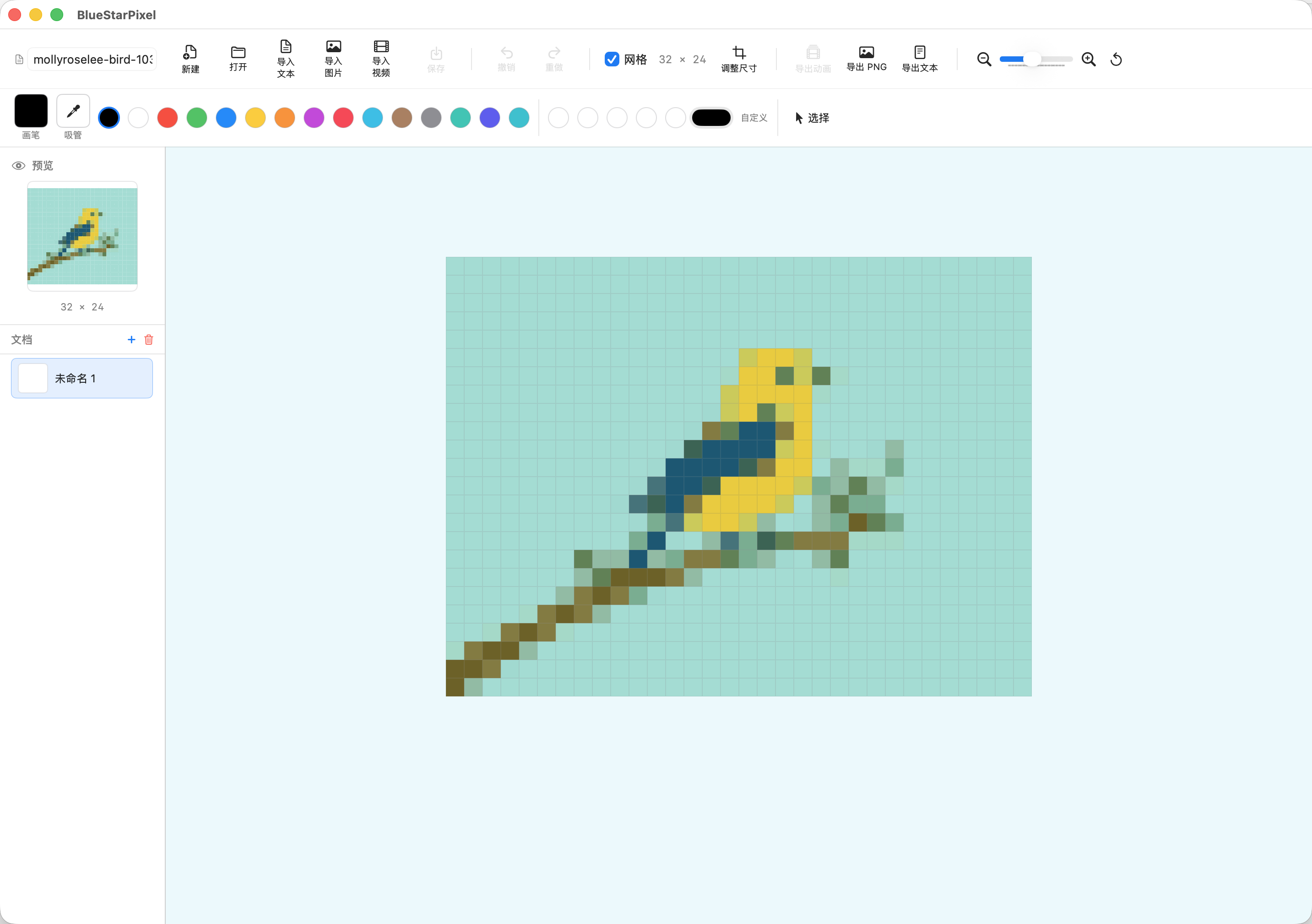
那么它对应的文本表示就如下:
palette
K 0.611765 0.870588 0.827451 1.000000
R 0.611009 0.870588 0.827451 1.000000
W 0.921078 0.801144 0.042974 1.000000
G 0.547549 0.741993 0.636601 1.000000
Y 0.515686 0.484804 0.225980 1.000000
B 0.620915 0.860131 0.779085 1.000000
O 0.052288 0.345752 0.454575 1.000000
M 0.601593 0.859355 0.814134 1.000000
P 0.448366 0.690850 0.560131 1.000000
A 0.427451 0.384314 0.115686 1.000000
C 0.359477 0.512418 0.316340 1.000000
D 0.797386 0.800327 0.280392 1.000000
E 0.205882 0.395098 0.326797 1.000000
F 0.245098 0.456209 0.481699 1.000000
grid
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK
KKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKK
KKKKKKKKKKKKKKKKDWWDKKKKKKKKKKKK
KKKKKKKKKKKKKRRBWWCDCBKKKKKKKKKK
KKKKKKKKKKKKRRRDWWWWBKKKKKKKKKKK
KKKKKKKKKKKRRRMDWCDWRKKKKKKKKKKK
KKKKKKKKKKRRRMYCOOYWKKKKKKKKKKKK
KKKKKKKKKRRRMEOOOODWBRKMGRKKKKKK
KKKKKKKKRRRMOOOOEYWWRGBBPRKKKKKK
KKKKKKKKRRMFOOEWWWWDPGCGBKKKKKKK
KKKKKKKRRMFEOYWWWWDRGCPPRKKKKKKK
KKKKKKRRRRMPFDWWDGRMGPACPRKKKKKK
KKKKKKRRRRPOMRGFPECYYYBBBKKKKKKK
KKKKKRRCGGOGPYYCPGMRGCRRKKKKKKKK
KKKRRRRGCAAAYGRRRRRRRBRKKKKKKKKK
RRRRRRGYAYPMRRRRRRRKKKKKKKKKKKKK
RRRRBYAYGRRRRRRRKKKKKKKKKKKKKKKK
RRBYAYBRRRRRRRKKKKKKKKKKKKKKKKKK
BYAAGRRRRRRRKKKKKKKKKKKKKKKKKKKK
AAYMRRRRRRRKKKKKKKKKKKKKKKKKKKKK
AGRRRRRRRKKKKKKKKKKKKKKKKKKKKKKK
我使用导出的文本、以及文本规则告诉AI,让AI帮我生成对应的像素动画,AI生成的效果都很难让人满意。AI还是理解不了其中的衣服、剑的意义,以及应该如何的“呼吸感”来制作动图。可能是我的提示词不够完善?Maybe。

使用生成好的像素图让AI生成动图,也是难以让人满意。

这个图里面不只是把刀识别成了尾巴,像是裙子、头发,以及头发上的高光都处理的不好。像是头发上的高光,AI似乎识别成了物体配饰,在动图中也跟着头发一起动了,按理来说高光应该需要随着头发动,而不断变化的。这是一些问题。还有的,像是刀剑挥砍时候的拖影等等,我觉得如果现在的AI能力还很难和专业画师媲美。
不过现在有一些AI制作的影片确实令人惊艳,虽说有些细节还是处理的不好,但是整体的效率、成本都非常惊人。不过要想追求极致,可能就需要花很多的时间进行反复试错和矫正。专业的人,在追求极致上还是很有优势的,就目前来说的话。(不知道目前这个词,还能用多久😂)。
另外想提一点是:
作为非专业画师,比如我想制作一个像素人物的待机动画,我的方式是:
-> 制作像素人物图
-> 使用某个AI扩展优化
-> 使用某个AI进行多角度视图创建、人物的多动作图创建
-> 使用某些已创建好的图进行待机动画视频、动图生成
在这个过程中,我会尽量想形成SOP,哪怕在某些时候喂给AI图片时需要提示词,我也会希望其提示词能够尽量统一,避免再每次使用的时候现场发挥,导致不一致。想要做到标准化、流水线般的SOP,这可能就是工程师思维吧?如果是让专业的画师来绘制人物的待机动画,大概会根据人物的特性,比如头发、武器等等来定制不同的画法,得到的效果图应该也要优秀得多。这就是一些不同点吧。
怎么说呢,拥抱AI吧。